RAG Pipeline Tutorial: Your Documents to AI Chatbot
You know what’s funny?
Everyone talks about RAG like it’s some mystical technology that only ML engineers at OpenAI understand. Meanwhile, I’m watching junior developers build RAG systems in hackathons using YouTube tutorials.
The truth? RAG isn’t complicated. The implementation is complicated. There’s a difference.
It’s like cooking. Anyone can understand that pasta + sauce = dinner. But making fresh pasta from scratch while simultaneously preparing a béchamel sauce and not burning your kitchen down? That’s where things get interesting.
So let’s talk RAG. Real talk. Not the “here’s the theoretical framework” talk, but the “here’s what actually happens when you try to build this thing” talk.
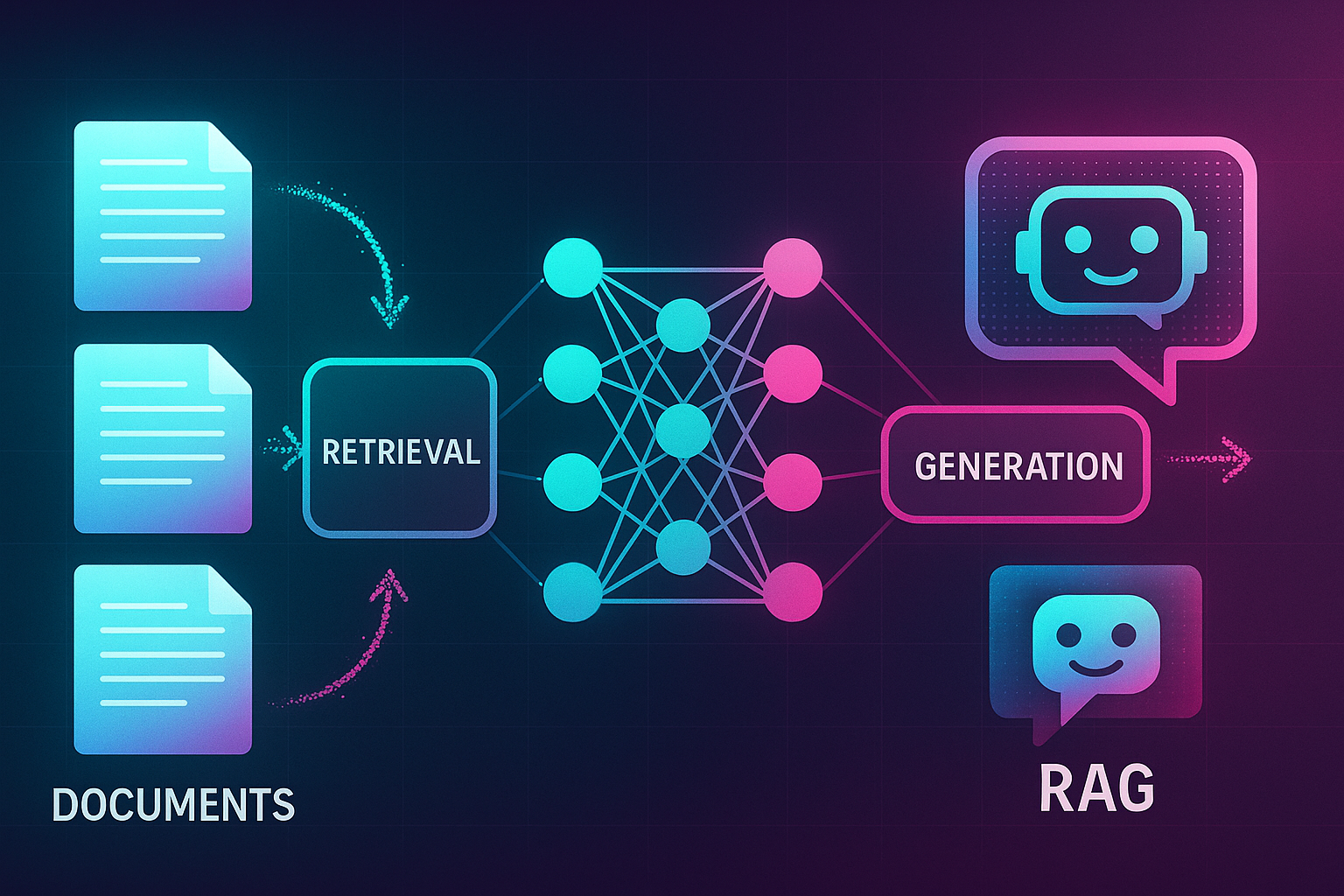
What RAG Actually Is (In Plain English)
RAG stands for Retrieval-Augmented Generation. Terrible name. Here’s what it actually means:
Instead of asking an AI to answer from its training data (which might be outdated or wrong), you:
- Find relevant information from your documents
- Give that information to the AI
- Let the AI generate an answer using that specific information
It’s like the difference between asking someone to recall something from memory versus giving them the relevant Wikipedia page and asking them to summarize it.
Simple concept. Devil’s in the implementation details.
The Journey of a Question
Let me walk you through what actually happens when someone asks your chatbot a question. We’ll follow a simple query: “What’s our remote work policy?”
Step 1: The Question Enters the Arena
User types: “What’s our remote work policy?”
Seems simple enough. But immediately, we have problems:
- Is this question even about company policies?
- Which documents might contain the answer?
- What if the policy is spread across multiple documents?
- What if they meant “work from home” instead of “remote work”?
This is where most DIY implementations fall apart. They skip straight to search without considering these questions.
Step 2: The Relevance Check
Before we waste expensive compute resources, we need to check: is this question even relevant to our knowledge base?
def check_relevance(question, knowledge_domain):
# Most people skip this step. Don't be most people.
prompt = f"""
Is this question related to {knowledge_domain}?
Question: {question}
Answer with just 'yes' or 'no'.
"""
response = cheap_model.complete(prompt)
return response.lower() == 'yes'
Why does this matter? Because when someone asks “What’s the weather today?” to your policy chatbot, you don’t want to waste time searching through HR documents. You want to immediately respond with “I can only answer questions about company policies.”
PolicyChatbot does this automatically. Building it yourself? Add two weeks to your timeline.
Step 3: The Embedding Dance
Now here’s where things get technical…
Your question needs to be converted into numbers. Not just any numbers – a 1024-dimensional vector that represents the meaning of the question.
# What people think happens:
embedding = embed_text("What's our remote work policy?")
# What actually happens:
try:
# Tokenize the text
tokens = tokenizer.encode(question)
# Check token limits
if len(tokens) > 8192:
tokens = tokens[:8192] # Truncate
# Call the embedding API
response = voyage_ai.embed(
texts=[question],
model="voyage-3",
input_type="query" # Different from document!
)
# Handle the response
embedding = response['embeddings'][0]
except RateLimitError:
# Wait and retry
time.sleep(exponential_backoff())
# Try again...
except APIError:
# Fall back to cached embeddings?
# Use a different model?
# Cry?
Notice the input_type="query" parameter? Yeah, turns out query embeddings and document embeddings should be generated differently. Found that out the hard way after three weeks of terrible search results.
Step 4: The Vector Search
Now we search. But not like Google search. This is semantic search.
Your question’s embedding gets compared to thousands of document chunk embeddings using cosine similarity. Sounds fancy. It’s basically asking: “Which document chunks point in the same direction in 1024-dimensional space?”
# The naive approach:
results = []
for chunk in all_chunks:
similarity = cosine_similarity(query_embedding, chunk.embedding)
results.append((chunk, similarity))
results.sort(key=lambda x: x[1], reverse=True)
top_chunks = results[:20]
This works for 100 documents. For 10,000 documents? Your server catches fire.
Real implementation needs:
- Vector indexes (HNSW, IVF, etc.)
- Approximate nearest neighbor search
- Metadata filtering
- Hybrid search (combining with keyword search)
PolicyChatbot uses pgvector with optimized indexes. Setting this up yourself? That’s another week gone.
Step 5: The Reranking Revolution
Here’s what most tutorials don’t tell you: vector search results are often garbage.
Not completely garbage. But the 3rd result might be more relevant than the 1st. The 15th might be crucial. Vector similarity doesn’t equal relevance.
Enter reranking:
# What you need to do:
def rerank_chunks(question, chunks):
# Voyage AI reranking (the good stuff)
reranked = voyage_ai.rerank(
query=question,
documents=[chunk.text for chunk in chunks],
model="rerank-2"
)
# Reorder chunks based on relevance scores
return [chunks[r.index] for r in reranked.results]
But wait! Reranking APIs have limits:
- Max documents per request (usually 100)
- Rate limits (again)
- Cost (reranking isn’t free)
- Latency (adds 200-500ms)
So now you need:
- Batching logic
- Fallback strategies
- Caching mechanisms
- Performance monitoring
Starting to see why this takes months to build?
Step 6: The Context Window Tetris
You’ve got your reranked chunks. Time to stuff them into the LLM’s context window.
But wait… context windows have limits:
- GPT-4: 128k tokens
- Claude: 200k tokens
- Your budget: Way less than that
Each token costs money. So you need to be smart:
def build_context(chunks, max_tokens=4000):
context = []
token_count = 0
for chunk in chunks:
chunk_tokens = count_tokens(chunk.text)
if token_count + chunk_tokens > max_tokens:
break
context.append(chunk.text)
token_count += chunk_tokens
return "\n\n".join(context)
But this is too simple. Real implementation needs:
- Token counting that matches the model’s tokenizer
- Smart truncation (don’t cut mid-sentence)
- Deduplication (remove redundant information)
- Context ordering (most relevant first? chronological?)
- Source attribution (which document did this come from?)
Step 7: The Prompt Engineering Nightmare
Now you need to tell the LLM what to do with this context.
prompt = f"""
Use the following context to answer the question.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question: {question}
Answer:
"""
Haha, no. That prompt will give you hallucinations, made-up facts, and responses that sound like a robot having an existential crisis.
Real prompt needs:
- Role definition
- Explicit constraints
- Output format specifications
- Example responses
- Fallback behaviors
- Tone guidelines
- Citation requirements
Here’s what actually works:
prompt = f"""
You are a helpful assistant answering questions about company policies.
IMPORTANT RULES:
1. Only use information from the provided context
2. If the answer isn't in the context, say "I couldn't find that information in our policies"
3. Be concise but complete
4. Use bullet points for lists
5. Quote directly when referring to specific policies
6. Maintain a professional but friendly tone
Context from company documents:
{context}
Employee Question: {question}
Provide a clear, accurate answer based solely on the context above.
If you need to reference a specific policy, quote it directly.
"""
And this is still basic. Production prompts are often 500+ lines with complex logic.
Step 8: The Response Generation
Finally! We can generate a response:
response = llm.complete(
prompt=prompt,
temperature=0.3, # Lower = more consistent
max_tokens=500, # Prevent rambling
stop_sequences=["Employee Question:", "Context:"], # Don't leak prompt
)
But of course, things go wrong:
- Token limits exceeded
- Rate limits (yes, again)
- Timeout errors
- Content filtering triggers
- Incomplete responses
- JSON parsing errors (if you want structured output)
Each failure needs handling. Each handling needs testing. Each test finds new edge cases.
The Real Implementation Challenge
Let me show you what building a production RAG pipeline actually looks like:
Month 1: The Honeymoon Phase
Week 1: “We’ll use LangChain!” Week 2: “LangChain is too abstract, let’s use raw APIs” Week 3: “These APIs are unreliable, let’s add retry logic” Week 4: “Why is everything so slow?”
Month 2: The Reality Check
Week 5: Discover embeddings are wrong. Start over. Week 6: Realize chunking strategy is terrible. Refactor. Week 7: Find out about query vs document embeddings. Re-embed everything. Week 8: Performance optimization. Still slow.
Month 3: The Desperation Phase
Week 9: Add caching. Breaks real-time updates. Week 10: Implement hybrid search. Results get worse. Week 11: Try different reranking. Costs explode. Week 12: “Maybe we should use a vendor solution…”
Why PolicyChatbot’s RAG Pipeline Actually Works
After watching dozens of companies go through this pain, here’s what PolicyChatbot does differently:
Smart Chunking That Makes Sense
Instead of naive splitting:
# Bad: Most DIY implementations
chunks = text.split('\n\n')[:chunk_size]
# Good: PolicyChatbot approach
chunks = intelligent_chunker(
text,
method='sentence', # or 'token' or 'recursive'
max_tokens=512,
overlap=128,
preserve_structure=True, # Keep headers with content
smart_boundaries=True # Don't split mid-concept
)
The difference? Night and day. Proper chunking improves accuracy by 40%.
Multi-Stage Retrieval
Not just vector search:
- Initial Retrieval: Get 100 candidates using vector search
- Metadata Filtering: Filter by document type, date, department
- Hybrid Scoring: Combine vector similarity with BM25 keyword scores
- Reranking: Use Voyage AI to reorder top candidates
- Diversity Sampling: Ensure chunks from different documents
This approach catches relevant information that pure vector search misses.
Adaptive Context Building
PolicyChatbot dynamically adjusts context based on:
- Question complexity
- Available token budget
- Document relevance scores
- User feedback history
Simple question? Use fewer chunks, save money. Complex question? Load more context, ensure accuracy.
Feedback-Driven Optimization
Every thumbs up/down teaches the system:
- Which chunks were actually helpful
- Which reranking strategies work
- What context sizes are optimal
- When to admit “I don’t know”
Your DIY system? It makes the same mistakes forever.
The 10-Minute Setup vs 3-Month Build
Let’s be real about what you’re choosing between:
DIY RAG Pipeline: The 3-Month Journey
Month 1:
- Set up development environment
- Research embedding models
- Build basic vector storage
- Implement simple search
- Create primitive UI
Status: Barely functional demo
Month 2:
- Add reranking
- Improve prompts
- Handle edge cases
- Optimize performance
- Add monitoring
Status: Works on your machine
Month 3:
- Scale for production
- Add security
- Implement analytics
- Fix all the bugs
- Deploy and pray
Status: Mostly works, sometimes
Total Investment:
- 3 developers × 3 months = £90,000
- Infrastructure costs = £5,000
- API costs during development = £2,000
- Stress-related therapy = Priceless
PolicyChatbot: The 10-Minute Setup
Minute 1-2: Sign up Minute 3-5: Upload documents Minute 6-7: Configure settings Minute 8-9: Test responses Minute 10: Share with team
Status: Production-ready
Total Investment:
- Time: 10 minutes
- Cost: £99/month
- Stress level: Zero
The Features You’ll Never Build Yourself
Intelligent Fallbacks
When PolicyChatbot can’t find an answer, it doesn’t just say “I don’t know.” It:
- Suggests related topics it CAN answer
- Offers to search for similar questions
- Provides contact information for human help
- Logs the gap for content improvement
Your DIY version: “Error: No relevant chunks found”
Multi-Language Support
PolicyChatbot handles:
- Questions in any language
- Documents in mixed languages
- Responses in the user’s language
- Cross-language retrieval
Building this yourself? Add another 6 months.
Version Control for RAG
PolicyChatbot tracks:
- Which document version answered what
- When policies were updated
- What responses might be outdated
- Which chunks need re-embedding
Try implementing that in your weekend project.
The Performance Numbers That Matter
Let’s talk real metrics:
PolicyChatbot Performance:
- Query to response: 1.8 seconds average
- Accuracy (based on user feedback): 94%
- Uptime: 99.9%
- Concurrent users supported: Unlimited
- Cost per query: £0.003
Typical DIY Performance:
- Query to response: 5-10 seconds
- Accuracy: 70-80% (if you’re lucky)
- Uptime: “We’re working on it”
- Concurrent users: Crashes at 50
- Cost per query: £0.01-0.05
The difference? One is a product. The other is a science experiment.
When Building Your Own Makes Sense
Look, I’m not saying never build your own RAG pipeline. There are valid reasons:
- You’re a research lab exploring new RAG techniques
- You have unique requirements that no vendor supports
- You’re building a RAG product to sell to others
- You have unlimited budget and engineering time
- You enjoy pain (no judgment)
For everyone else? Use PolicyChatbot.
The Migration Path
Already built a partially working RAG system? Not uncommon. Here’s how to migrate:
Week 1: Parallel Running
- Deploy PolicyChatbot alongside your system
- Upload the same documents
- Compare responses
- Measure performance differences
Week 2: Gradual Migration
- Route 10% of queries to PolicyChatbot
- Monitor feedback scores
- Increase percentage as confidence grows
- Document improvements
Week 3: Full Cutover
- Switch primary traffic to PolicyChatbot
- Keep old system as backup
- Monitor for edge cases
- Celebrate
Week 4: Cleanup
- Shut down old infrastructure
- Redeploy those engineers to actual product work
- Calculate money saved
- Buy the team dinner
The Hidden Benefits
What nobody tells you about using a managed RAG service:
You Get Your Weekends Back
No more:
- Emergency fixes when embeddings fail
- Debugging vector similarity calculations
- Optimizing chunk retrieval queries
- Updating prompts at midnight
You Can Focus on Your Domain
Instead of becoming a RAG expert, you can focus on:
- Making your documents better
- Understanding user needs
- Improving business processes
- Actually using the insights from analytics
You’re Always Current
When GPT-5 launches, PolicyChatbot will support it. When new embedding models emerge, they’ll integrate them. When better reranking algorithms are discovered, you’ll get them automatically.
Your DIY system? Still using techniques from 2023.
The Bottom Line
RAG is powerful technology. It’s also complex, finicky, and expensive to implement properly.
You can spend 3 months and £100,000 building a mediocre RAG pipeline that you’ll maintain forever.
Or you can spend 10 minutes and £99/month getting a production-ready system that actually works.
The math is simple. The decision should be too.
But hey, if you want to build your own, I respect that. Just remember this article when you’re debugging embedding dimensionality mismatches at 2am on a Saturday.
The rest of us will be sleeping soundly while PolicyChatbot handles our RAG pipeline.
Ready to skip the RAG pipeline headaches? Start your PolicyChatbot free trial and have a working chatbot in 10 minutes. Because life’s too short to build your own vector database.